- 手机:138 0000 0000
- 传真:+86-123-4567
- 全国服务热线:400-123-4567


本人是做自动驾驶决策方向,最近在学习强化学习,我看大部分用强化学习做决策都是端到端的,想请问一下各位大佬们,能不能把强化学习与传统的路径规划算法结合起来?只用强化学习做行为决策,产生一个决策意图,然后用二次规划之类的做详细的局部路径规划呢
传统路径规划是planning吧?那就是现在的model based reinforcement learning
传统路径规划指的是进化计算那些的话,其实二者并不是特别好结合。ML崇尚端对端搜索,而进化计算推行启发式搜索。这几年RL搞优化已经很多了,一篇经典文章attention, learn to solve routing problems 送给你
可以,并且百度等先驱已经对类似的想法进行了落地。
决策策略由两部分构成:规划算法可以提供多条待择轨迹,然后用强化学习做轨迹筛选。
至于训练方法,就把这种组合策略放在一个模拟器里端到端训练即可。实验证明,在一定场景下,组合策略的效果可以超过单一的规划策略。
Q-learning算法是强化学习算法中的一种,该算法主要包含:Agent、状态、动作、环境、回报和惩罚。Q-learning算法通过机器人与环境不断地交换信息,来实现自我学习。Q-learning算法中的Q表是机器人与环境交互后的结果,因此在Q-learning算法中更新Q表就是机器人与环境的交互过程。机器人在当前状态s(t)下,选择动作a,通过环境的作用,形成新的状态s(t+1),并产生回报或惩罚r(t+1),通过式(1)更新Q表后,若Q(s,a)值变小,则表明机器人处于当前位置时选择该动作不是最优的,当下次机器人再次处于该位置或状态时,机器人能够避免再次选择该动作action. 重复相同的步骤,机器人与环境之间不停地交互,就会获得到大量的数据,直至Q表收敛。QL算法使用得到的数据去修正自己的动作策略,然后继续同环境进行交互,进而获得新的数据并且使用该数据再次改良它的策略,在多次迭代后,Agent最终会获得最优动作。在一个时间步结束后,根据上个时间步的信息和产生的新信息更新Q表格,Q(s,a)更新方式如式(1):
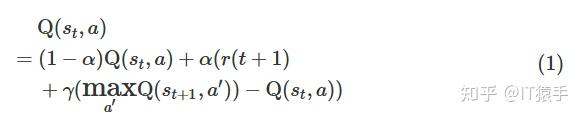
式中:st为当前状态;r(t+1)为状态st的及时回报;a为状态st的动作空间;α为学习速率,α∈[0,1];γ为折扣速率,γ∈[0,1]。当α=0时,表明机器人只向过去状态学习,当α=1时,表明机器人只能学习接收到的信息。当γ=1时,机器人可以学习未来所有的奖励,当γ=0时,机器人只能接受当前的及时回报。
每个状态的最优动作通过式(2)产生:
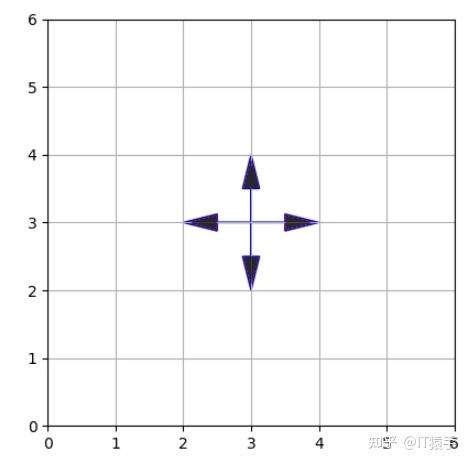
Q-learning算法的搜索方向为上下左右四个方向,如下图所示:
Q-learning算法基本原理参考文献:
[1]王付宇,张康,谢昊轩等.基于改进Q-learning算法的移动机器人路径优化[J].系统工程,2022,40(04):100-109.
部分代码:提供参考地图,地图数值可以修改(地图中0代表障碍物,50代表通道 ,70代表起点 ,100代表终点),最大训练次数等参数可根据自己需要修改。
close all
clear
clc
%reference code link: https://mbd.pub/o/bread/ZJqcm59u
global maze2D;
global tempMaze2D;
NUM_ITERATIONS=700; % 最大训练次数(可以修改)
DISPLAY_FLAG=0; % 是否显示(1 显示; 0 不显示)注意:设置为0运行速度更快
CurrentDirection=4; % 当前机器人的朝向(1-4具体指向如下)
% 1 - means robot facing up
% 2 - means robot facing left
% 3 - means robot facing right
% 4 - means robot facing down
maze2D=xlsread('10x10.xlsx');%%导入地图(提供5个地图,可以修改) maze2D中 0代表障碍物 50代表通道 70代表起点 100代表终点
[startX,startY]=find(maze2D==70);%获取起点
[goalX,goalY]=find(maze2D==100);%获取终点
orgMaze2D=maze2D;
tempMaze2D=orgMaze2D;
CorlorStr='jet';
%reference code link: https://mbd.pub/o/bread/ZJqcm59u
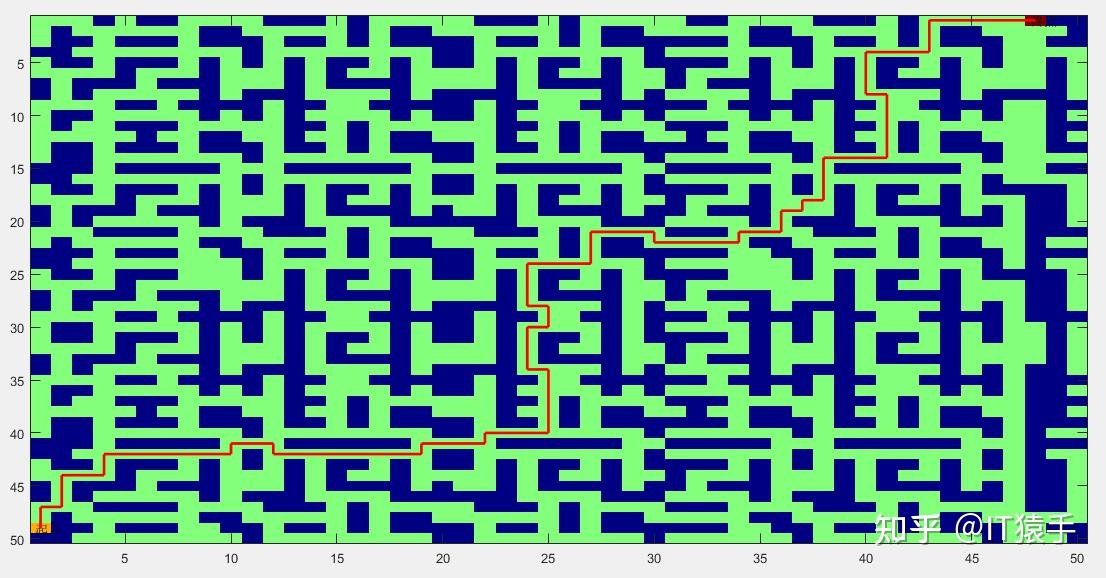
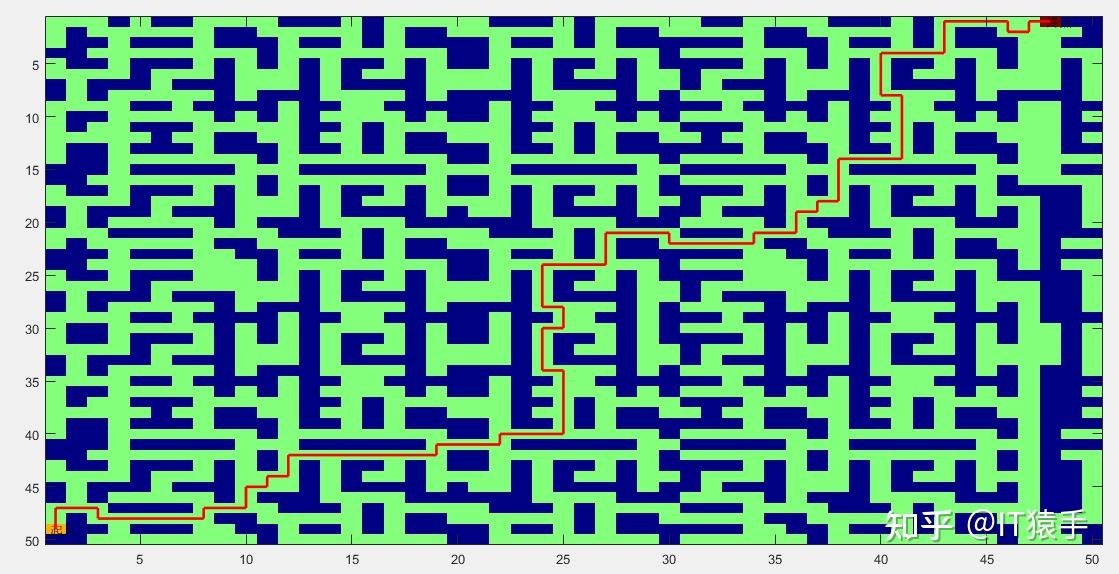
地图中绿色为通道,蓝色为障碍物,红线为得到的路径,起始点均标注。
机器人最终路径:
49 1
48 1
47 1
47 2
47 3
48 3
48 4
48 5
48 6
48 7
48 8
47 8
47 9
47 10
46 10
45 10
45 11
45 12
44 12
43 12
42 12
42 13
42 14
42 15
42 16
42 17
42 18
42 19
41 19
41 20
41 21
41 22
40 22
40 23
40 24
40 25
39 25
38 25
37 25
36 25
35 25
34 25
34 24
33 24
32 24
31 24
30 24
30 25
29 25
28 25
28 24
27 24
26 24
25 24
24 24
24 25
24 26
24 27
23 27
22 27
21 27
21 28
21 29
21 30
22 30
22 31
22 32
22 33
22 34
21 34
21 35
21 36
20 36
19 36
18 36
17 36
16 36
15 36
15 37
15 38
14 38
14 39
14 40
14 41
13 41
12 41
11 41
10 41
9 41
8 41
8 40
7 40
6 40
5 40
4 40
4 41
4 42
4 43
3 43
2 43
1 43
1 44
1 45
1 46
1 47
2 47
2 48
1 48
机器人最终路径长度为 107
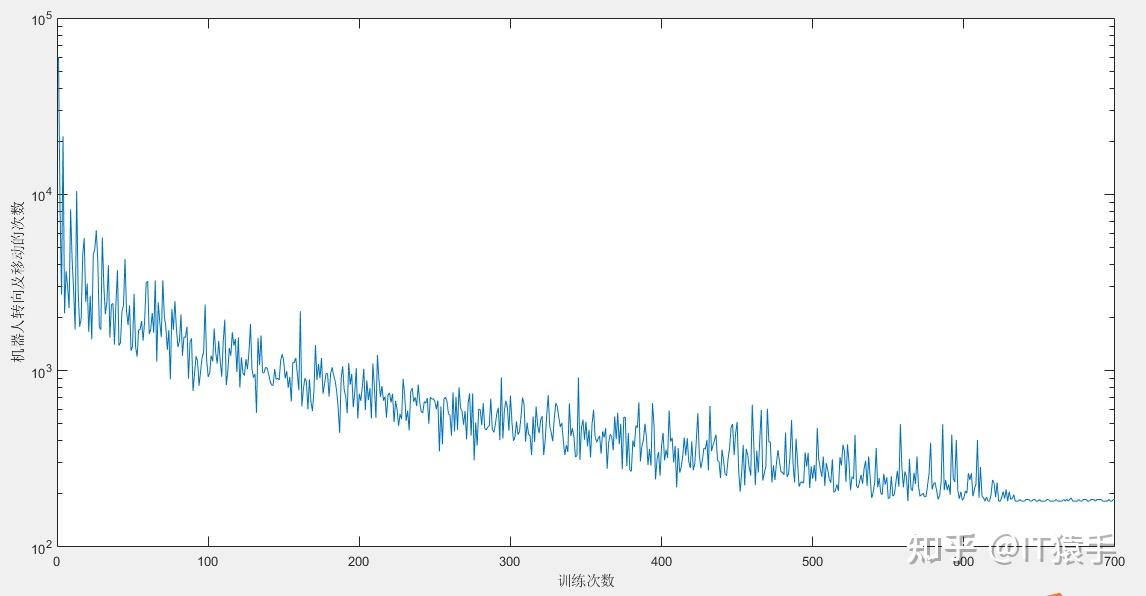
机器人在最终路径下的转向及移动次数为 189

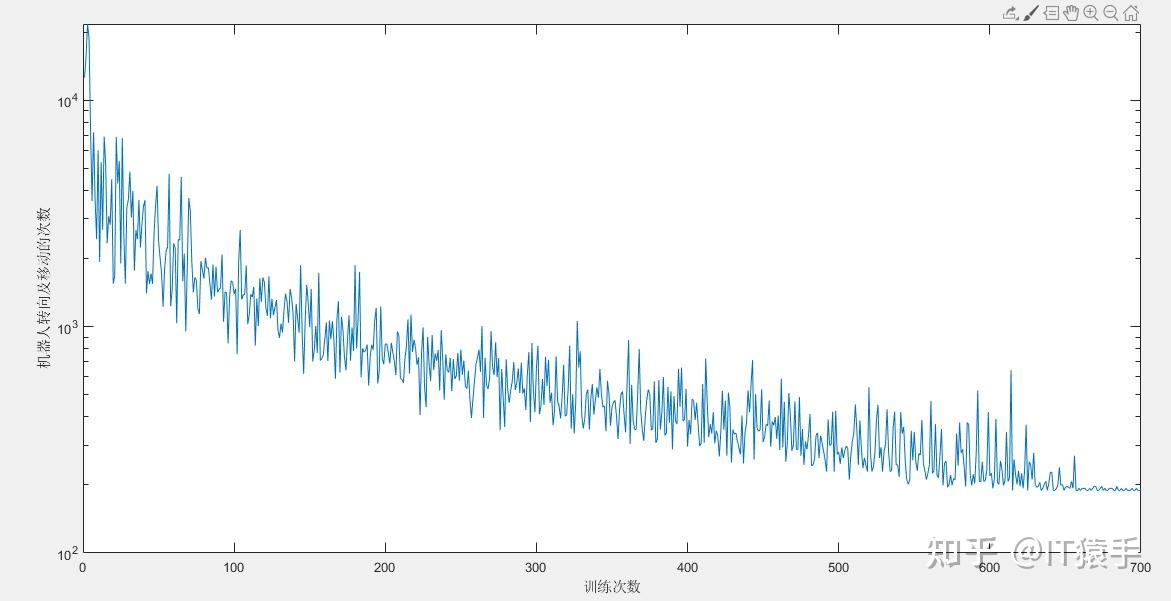
机器人最终路径:
49 1
48 1
47 1
47 2
46 2
45 2
44 2
44 3
44 4
43 4
42 4
42 5
42 6
42 7
42 8
42 9
42 10
41 10
41 11
41 12
42 12
42 13
42 14
42 15
42 16
42 17
42 18
42 19
41 19
41 20
41 21
41 22
40 22
40 23
40 24
40 25
39 25
38 25
37 25
36 25
35 25
34 25
34 24
33 24
32 24
31 24
30 24
30 25
29 25
28 25
28 24
27 24
26 24
25 24
24 24
24 25
24 26
24 27
23 27
22 27
21 27
21 28
21 29
21 30
22 30
22 31
22 32
22 33
22 34
21 34
21 35
21 36
20 36
19 36
19 37
18 37
18 38
17 38
16 38
15 38
14 38
14 39
14 40
14 41
13 41
12 41
11 41
10 41
9 41
8 41
8 40
7 40
6 40
5 40
4 40
4 41
4 42
4 43
3 43
2 43
1 43
1 44
1 45
1 46
1 47
1 48
机器人最终路径长度为 105
机器人在最终路径下的转向及移动次数为 186
机器人最终路径:
49 1
48 1
47 1
47 2
47 3
48 3
48 4
48 5
48 6
48 7
48 8
47 8
47 9
47 10
46 10
45 10
45 11
44 11
44 12
43 12
42 12
42 13
42 14
42 15
42 16
42 17
42 18
42 19
41 19
41 20
41 21
41 22
40 22
40 23
40 24
40 25
39 25
38 25
37 25
36 25
35 25
34 25
34 24
33 24
32 24
31 24
30 24
30 25
29 25
28 25
28 24
27 24
26 24
25 24
24 24
24 25
24 26
24 27
23 27
22 27
21 27
21 28
21 29
21 30
22 30
22 31
22 32
22 33
22 34
21 34
21 35
21 36
20 36
19 36
19 37
18 37
18 38
17 38
16 38
15 38
14 38
14 39
14 40
14 41
13 41
12 41
11 41
10 41
9 41
8 41
8 40
7 40
6 40
5 40
4 40
4 41
4 42
4 43
3 43
2 43
1 43
1 44
1 45
1 46
2 46
2 47
1 47
1 48
机器人最终路径长度为 107
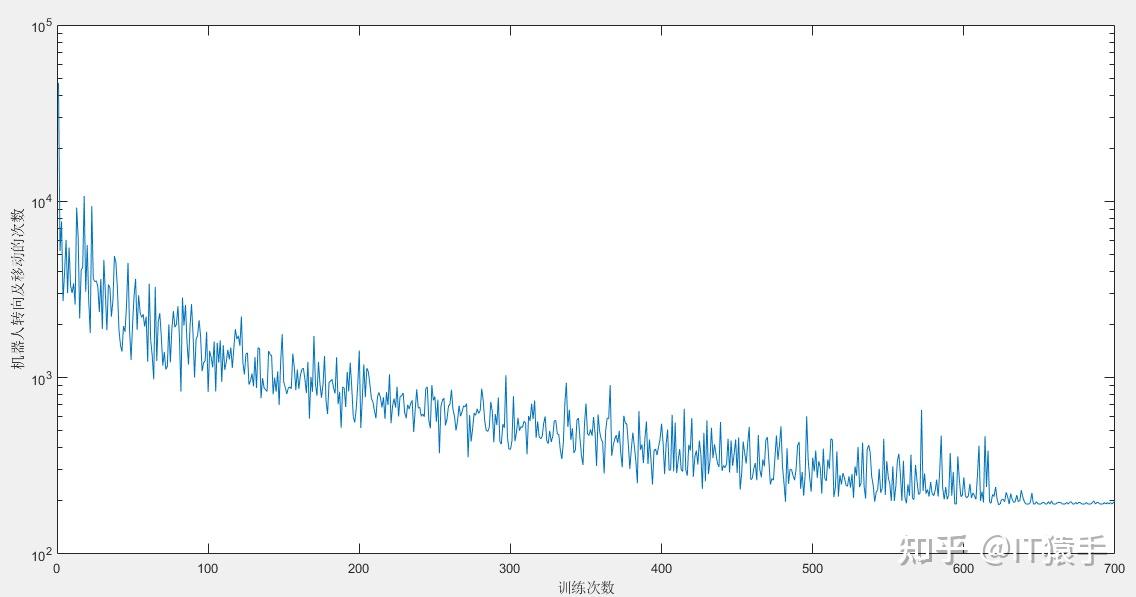
机器人在最终路径下的转向及移动次数为 200
本文介绍基于SUMO与gym组合的强化学习demo。
本文主要采用的依赖包版本如下:
gym==0.21.0
stable-baselines3==1.8.0SUMO 软件的版本为1.8.0
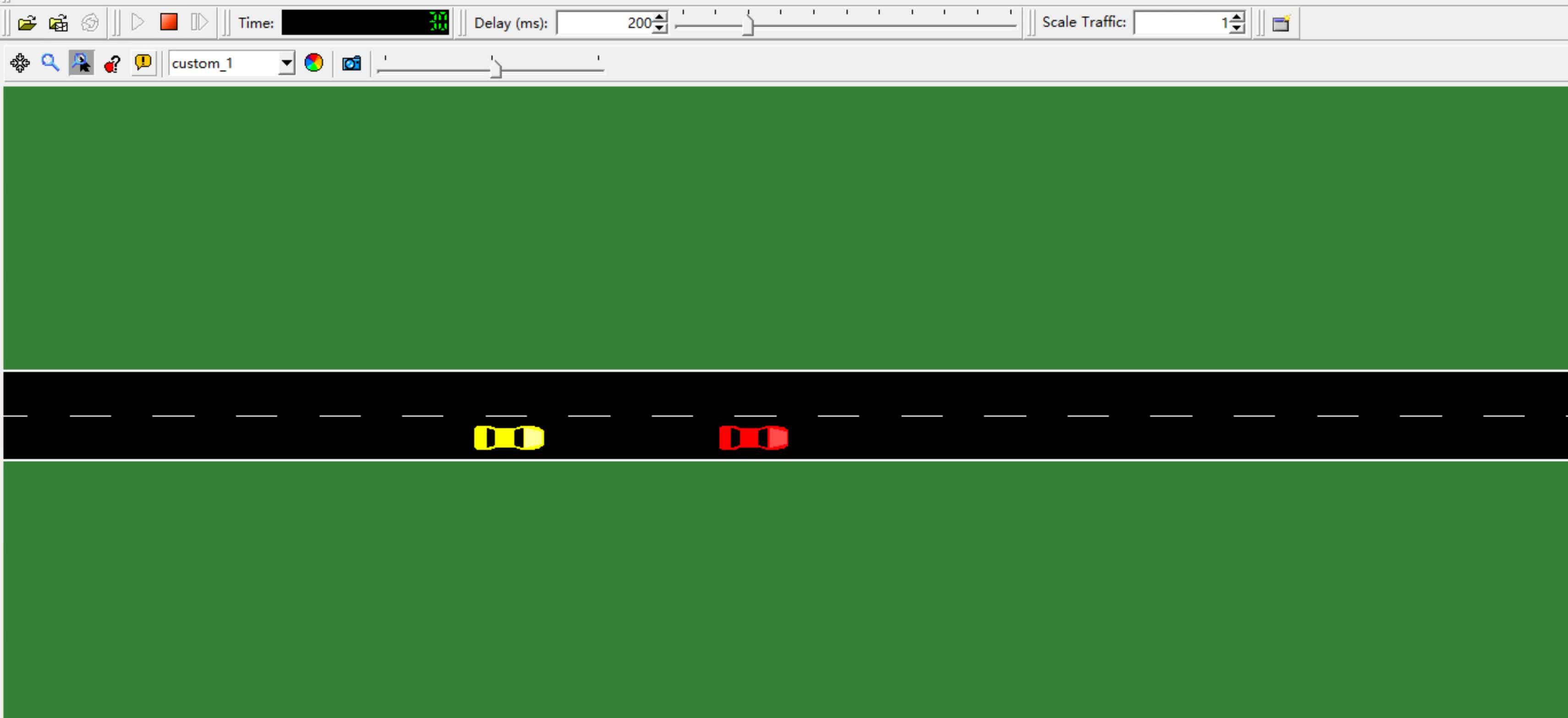
高速直行两车道,车辆A和车辆B沿着同一车道直行。车辆A为前车,车辆B为后车,前车A为慢车最高车速为10m/s,后车B为快车,最高车速为25m/s,如下图。决策任务:车辆B通过换道至左侧车道超过A车。

道路配置文件:JingZan.net.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- generated on 09/06/23 16:56:12 by Eclipse SUMO netedit Version 1.8.0
<configuration xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://sumo.dlr.de/xsd/netconvertConfiguration.xsd">
<input>
<sumo-net-file value="D:\\code\\Motion_Planning\\SumoGym\\sumo_config\\JingZan.net.xml"/>
</input>
<output>
<output-file value="D:\\code\\Motion_Planning\\SumoGym\\sumo_config\\JingZan.net.xml"/>
</output>
<processing>
<geometry.min-radius.fix.railways value="false"/>
<geometry.max-grade.fix value="false"/>
<offset.disable-normalization value="true"/>
<lefthand value="false"/>
</processing>
<junctions>
<no-turnarounds value="true"/>
<junctions.corner-detail value="5"/>
<junctions.limit-turn-speed value="5.5"/>
<rectangular-lane-cut value="false"/>
</junctions>
<pedestrian>
<walkingareas value="false"/>
</pedestrian>
<report>
<aggregate-warnings value="5"/>
</report>
</configuration>
-->
<net version="1.6" junctionCornerDetail="5" limitTurnSpeed="5.50" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://sumo.dlr.de/xsd/net_file.xsd">
<location netOffset="0.00,0.00" convBoundary="0.00,0.00,2000.00,0.00" origBoundary="-10000000000.00,-10000000000.00,10000000000.00,10000000000.00" projParameter="!"/>
<edge id=":gneJ1_0" function="internal">
<lane id=":gneJ1_0_0" index="0" speed="30.00" length="0.10" shape="1000.00,-4.80 1000.00,-4.80"/>
<lane id=":gneJ1_0_1" index="1" speed="30.00" length="0.10" shape="1000.00,-1.60 1000.00,-1.60"/>
</edge>
<edge id="gneE0" from="gneJ0" to="gneJ1" priority="-1">
<lane id="gneE0_0" index="0" speed="30.00" length="1000.00" shape="0.00,-4.80 1000.00,-4.80"/>
<lane id="gneE0_1" index="1" speed="30.00" length="1000.00" shape="0.00,-1.60 1000.00,-1.60"/>
</edge>
<edge id="gneE1" from="gneJ1" to="gneJ2" priority="-1">
<lane id="gneE1_0" index="0" speed="30.00" length="1000.00" shape="1000.00,-4.80 2000.00,-4.80"/>
<lane id="gneE1_1" index="1" speed="30.00" length="1000.00" shape="1000.00,-1.60 2000.00,-1.60"/>
</edge>
<junction id="gneJ0" type="dead_end" x="0.00" y="0.00" incLanes="" intLanes="" shape="0.00,0.00 0.00,-6.40"/>
<junction id="gneJ1" type="priority" x="1000.00" y="0.00" incLanes="gneE0_0 gneE0_1" intLanes=":gneJ1_0_0 :gneJ1_0_1" shape="1000.00,0.00 1000.00,-6.40 1000.00,0.00">
<request index="0" response="00" foes="00" cont="0"/>
<request index="1" response="00" foes="00" cont="0"/>
</junction>
<junction id="gneJ2" type="dead_end" x="2000.00" y="0.00" incLanes="gneE1_0 gneE1_1" intLanes="" shape="2000.00,-6.40 2000.00,0.00"/>
<connection from="gneE0" to="gneE1" fromLane="0" toLane="0" via=":gneJ1_0_0" dir="s" state="M"/>
<connection from="gneE0" to="gneE1" fromLane="1" toLane="1" via=":gneJ1_0_1" dir="s" state="M"/>
<connection from=":gneJ1_0" to="gneE1" fromLane="0" toLane="0" dir="s" state="M"/>
<connection from=":gneJ1_0" to="gneE1" fromLane="1" toLane="1" dir="s" state="M"/>
</net>
路线配置文件:my_route1.rou.xml
<routes>
<vType id="CarA" accel="2.5" decel="4.5" emergencyDecel="9.0" length="5" color="1,1,0" vClass="passenger" maxSpeed="25" carFollowModel="IDM"/>
<vType id="CarB" accel="2.5" decel="4.5" emergencyDecel="9.0" length="5" color="1,1,0" vClass="passenger" maxSpeed="10" carFollowModel="IDM"/>
<route id="route1" edges="gneE0 gneE1" />
<vehicle id="vehicle1" depart="0" departLane="0" arrivalLane="0" departPos="3" departSpeed="1" route="route1" type="CarB" color="1,0,0"/>
<vehicle id="self_car" depart="5" departLane="0" arrivalLane="0" departPos="3" departSpeed="1" route="route1" type="CarA" color="1,1,0"/>
</routes>
SUMO配置文件:my_config_file.sumocfg
<configuration>
<input>
<net-file value="JingZan.net.xml"/>
<route-files value="my_route1.rou.xml"/>
</input>
<time>
<begin value="0"/>
<end value="100"/>
</time>
<gui_only>
<start value="t"/>
<quit-on-end value="t"/>
</gui_only>
<processing>
<lanechange.duration value="5"/>
</processing>
</configuration>
"""
@Author: Fhz
@Create Date: 2023/9/6 17:18
@File: sumoTest.py
@Description:
@Modify Person Date:
"""
import sys
import os
import time
if 'SUMO_HOME' in os.environ:
tools = os.path.join(os.environ['SUMO_HOME'], 'tools')
sys.path.append(tools)
else:
sys.exit("Please declare environment variable 'SUMO_HOME'")
import traci
from sumolib import checkBinary
if_show_gui = True
if not if_show_gui:
sumoBinary = checkBinary('sumo')
else:
sumoBinary = checkBinary('sumo-gui')
sumocfgfile = "sumo_config/my_config_file.sumocfg"
traci.start([sumoBinary, "-c", sumocfgfile])
SIM_STEPS = [1, 100]
beginTime = SIM_STEPS[0]
duration = SIM_STEPS[1]
time.sleep(2)
egoID = "self_car"
for step in range(duration):
traci.simulationStep(step)
traci.vehicle.changeLane("self_car", "{}".format(0), 5)
测试视频如下
 https://www.zhihu.com/video/1682871587651698689
https://www.zhihu.com/video/1682871587651698689自定义gym强化学习环境的建立见文章:基于自定义gym环境的强化学习
动作空间:离散动作{0:车道保持;1:左换道},底层采用IDM跟车模型与SUMO默认换道模型。
状态空间:车辆B和车辆A的状态{x, y, speed}。
奖励函数: 奖励函数由时间奖励、目标车道奖励、期望速度奖励和安全奖励组成。
终止条件:{1:完成超车;2:任务超时;3:发生碰撞}
"""
@Author: Fhz
@Create Date: 2023/9/6 19:52
@File: sumoGym.py
@Description:
@Modify Person Date:
"""
import os
import sys
# check if SUMO_HOME exists in environment variable
# if not, then need to declare the variable before proceeding
# makes it OS-agnostic
if "SUMO_HOME" in os.environ:
tools = os.path.join(os.environ["SUMO_HOME"], "tools")
sys.path.append(tools)
else:
sys.exit("please declare environment variable 'SUMO_HOME'")
import gym
from gym import spaces
import numpy as np
import traci
from sumolib import checkBinary
from stable_baselines3 import PPO
import time
import argparse
class SumoGym(gym.Env):
def __init__(self, args):
self.current_state = None
self.is_success = False
self.show_gui = args.show_gui
self.sumocfgfile = args.sumocfgfile
self.egoID = args.egoID
self.frontID = args.frontID
self.start_time = args.start_time
self.collision = args.collision
self.sleep = args.sleep
self.num_action = args.num_action
self.lane_change_time = args.lane_change_time
# Road config
self.min_x_position = args.min_x_position
self.max_x_position = args.max_x_position
self.min_y_position = args.min_y_position
self.max_y_position = args.max_y_position
self.min_speed = args.min_speed
self.max_speed = args.max_speed
# Reward config
self.w_time = args.w_time
self.w_lane = args.w_lane
self.w_speed = args.w_speed
self.R_time = args.R_time
self.P_lane = args.P_lane
self.V_desired = args.V_desired
self.R_collision = args.R_collision
# Done config
self.target_lane_id = args.target_lane_id
self.max_count = args.max_count
self.low = np.array([
# ego vehicle
self.min_x_position,
self.min_y_position,
self.min_speed,
# ego leader
self.min_x_position,
self.min_y_position,
self.min_speed,
], dtype=np.float32)
self.high = np.array([
# ego vehicle
self.max_x_position,
self.max_y_position,
self.max_speed,
# ego_leader
self.max_x_position,
self.max_y_position,
self.max_speed,
], dtype=np.float32)
self.action_space = spaces.Discrete(self.num_action)
self.observation_space = spaces.Box(self.low, self.high, dtype=np.float32)
def step(self, action):
assert self.action_space.contains(action), "%r (%s) invalid" % (
action,
type(action),
)
if self.is_success:
self.is_success = False
if self.collision:
self.collision = False
self.count = self.count + 1
traci.simulationStep(self.count)
egoLane = traci.vehicle.getLaneIndex(self.egoID)
if action == 0:
traci.vehicle.changeLane(self.egoID, "{}".format(0), self.lane_change_time) # lane keeping
else:
traci.vehicle.changeLane(self.egoID, "{}".format(1), self.lane_change_time) # lane change
self.current_state = self.getCurrentStates()
Collision_Nums = traci.simulation.getCollidingVehiclesNumber()
if Collision_Nums:
print("collision num:{}".format(Collision_Nums))
self.collision = True
done = self.getDoneState(egoLane)
reward = self.getRewards()
info = {}
if done:
traci.close()
return self.current_state, reward, done, info
def render(self):
self.show_gui = True
pass
def reset(self):
self.collision = False
if self.show_gui:
sumoBinary = checkBinary('sumo-gui')
else:
sumoBinary = checkBinary('sumo')
traci.start([sumoBinary, "-c", self.sumocfgfile])
if self.sleep:
time.sleep(2)
for step in range(self.start_time):
self.count = step + 1
traci.simulationStep(self.count)
if self.count >= 5:
traci.vehicle.changeLane(self.egoID, "{}".format(0), self.lane_change_time)
return self.getCurrentStates()
def getVehicleStateViaId(self, vehicle_ID):
"""
vehicle_ID: vehicle ID
function: Get the Vehicle's state via vehicle ID
"""
curr_pos = traci.vehicle.getPosition(vehicle_ID)
y_ego, x_ego = curr_pos[0], curr_pos[1]
speed = traci.vehicle.getSpeed(vehicle_ID)
return x_ego, y_ego, speed
def getCurrentStates(self):
"""
function: Get all the states of vehicles, observation space.
"""
x_ego, y_ego, speed_ego = self.getVehicleStateViaId(self.egoID)
x_front, y_front, speed_front = self.getVehicleStateViaId(self.frontID)
self.current_state = [x_ego, y_ego, speed_ego, x_front, y_front, speed_front]
return self.current_state
def getRewards(self):
"""
function: get the reward after action.
"""
# Efficient reward
R_time = - self.R_time
R_lane = -abs(self.current_state[0] - self.P_lane)
R_speed = -abs(self.current_state[2] - self.V_desired)
R_eff = self.w_time * R_time + self.w_lane * R_lane + self.w_speed * R_speed
# Safety Reward
if self.collision:
R_safe = self.R_collision
else:
R_safe = 0
R_eff = max(-30, R_eff)
R_safe = max(-500, R_safe)
Rewards = R_eff + R_safe
return Rewards
def getDoneState(self, ego_lane):
"""
function: get the done state of simulation.
"""
done = False
if ego_lane == self.target_lane_id and self.current_state[1] >= self.current_state[4] + 30:
done = True
print("Mission success!")
self.is_success = True
return done
if self.count >= self.max_count:
done = True
print("Exceeding maximum time!")
return done
if self.collision:
done = True
print("Collision occurs!")
return done
return done
def get_args():
parser = argparse.ArgumentParser()
# SUMO config
parser.add_argument("--show_gui", type=bool, default=False, help="The flag of show SUMO gui.")
parser.add_argument("--sumocfgfile", type=str, default="sumo_config/my_config_file.sumocfg", help="The path of the SUMO configure file.")
parser.add_argument("--egoID", type=str, default="self_car", help="The ID of ego vehicle.")
parser.add_argument("--frontID", type=str, default="vehicle1", help="The ID of front vehicle.")
parser.add_argument("--start_time", type=int, default=10, help="The simulation step before learning.")
parser.add_argument("--num_action", type=int, default=2, help="The number of action space.")
parser.add_argument("--lane_change_time", type=float, default=5, help="The time of lane change.")
# Road config
parser.add_argument("--min_x_position", type=float, default=0.0, help="The minimum lateral position of vehicle.")
parser.add_argument("--max_x_position", type=float, default=6.4, help="The maximum lateral position of vehicle.")
parser.add_argument("--min_y_position", type=float, default=0.0, help="The minimum longitudinal position of vehicle.")
parser.add_argument("--max_y_position", type=float, default=2000.0, help="The maximum longitudinal position of vehicle.")
parser.add_argument("--min_speed", type=float, default=0.0, help="The minimum longitudinal speed of vehicle.")
parser.add_argument("--max_speed", type=float, default=25.0, help="The maximum longitudinal speed of vehicle.")
parser.add_argument("--count", type=int, default=0, help="The length of a training episode.")
parser.add_argument("--collision", type=bool, default=False, help="The flag of collision of ego vehicle.")
parser.add_argument("--sleep", type=bool, default=True, help="The flag of sleep of each simulation.")
# Reward config
parser.add_argument("--w_time", type=float, default=0.1, help="The weight of time consuming reward.")
parser.add_argument("--w_lane", type=float, default=2, help="The weight of target lane reward.")
parser.add_argument("--w_speed", type=float, default=0.1, help="The weight of desired speed reward.")
parser.add_argument("--R_time", type=float, default=-1, help="The reward of time consuming.")
parser.add_argument("--P_lane", type=float, default=-1.6, help="The lateral position of target lane.")
parser.add_argument("--V_desired", type=float, default=20.0, help="The desired speed.")
parser.add_argument("--R_collision", type=float, default=-400, help="The reward of ego vehicle collision.")
# Done config
parser.add_argument("--target_lane_id", type=int, default=1, help="The ID of target lane.")
parser.add_argument("--max_count", type=int, default=25, help="The maximum length of a training episode.")
args = parser.parse_args()
return args环境测试:
if __name__ == '__main__':
args = get_args()
env = SumoGym(args)
ACTIONS_ALL = {
0: 'Lane keeping',
1: 'Lane change',
}
eposides = 10
for eq in range(eposides):
print("Test eposide:{}".format(eq))
obs = env.reset()
done = False
rewards = 0
counts = 0
while not done:
counts += 1
time.sleep(0.01)
action = env.action_space.sample()
# print("The action is:{}".format(ACTIONS_ALL[action]))
obs, reward, done, info = env.step(action)
# env.render()
rewards += reward
print("The rewards is:{}, the counts is:{}".format(rewards, counts))测试结果如下:
Test eposide: 0
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.176627402856454, the counts is: 11
Test eposide: 1
Loading configuration ... done.
Exceeding maximum time!
Step #25.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -55.62561542130102, the counts is: 15
Test eposide: 2
Loading configuration ... done.
Exceeding maximum time!
Step #25.00 (0ms ?*RT. ?UPS, TraCI: 1ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -51.78561542130102, the counts is: 15
Test eposide: 3
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -23.61662740285646, the counts is: 11
Test eposide: 4
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.176627402856454, the counts is: 11
Test eposide: 5
Loading configuration ... done.
Exceeding maximum time!
Step #25.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -56.31834670955517, the counts is: 15
Test eposide: 6
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 1ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -22.336627402856458, the counts is: 11
Test eposide: 7
Loading configuration ... done.
Mission success!
Step #24.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -43.87270032448571, the counts is: 14
Test eposide: 8
Loading configuration ... done.
Exceeding maximum time!
Step #25.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -51.78561542130102, the counts is: 15
Test eposide: 9
Loading configuration ... done.
Exceeding maximum time!
Step #25.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -55.91591460997491, the counts is: 15由测试结果可知,任务成功率为:5/10=0.5。
采用的强化学习算法为PPO,模型训练:
if __name__ == '__main__':
args = get_args()
env = SumoGym(args)
model = PPO('MlpPolicy', env,
policy_kwargs=dict(net_arch=[64, 64]),
learning_rate=5e-4,
batch_size=32,
gamma=0.99,
verbose=1,
tensorboard_log="logs/",
)
model.learn(int(4e4))
model.save("models/ppo1")训练过程训练20000步,大概2小时,训练曲线如下::
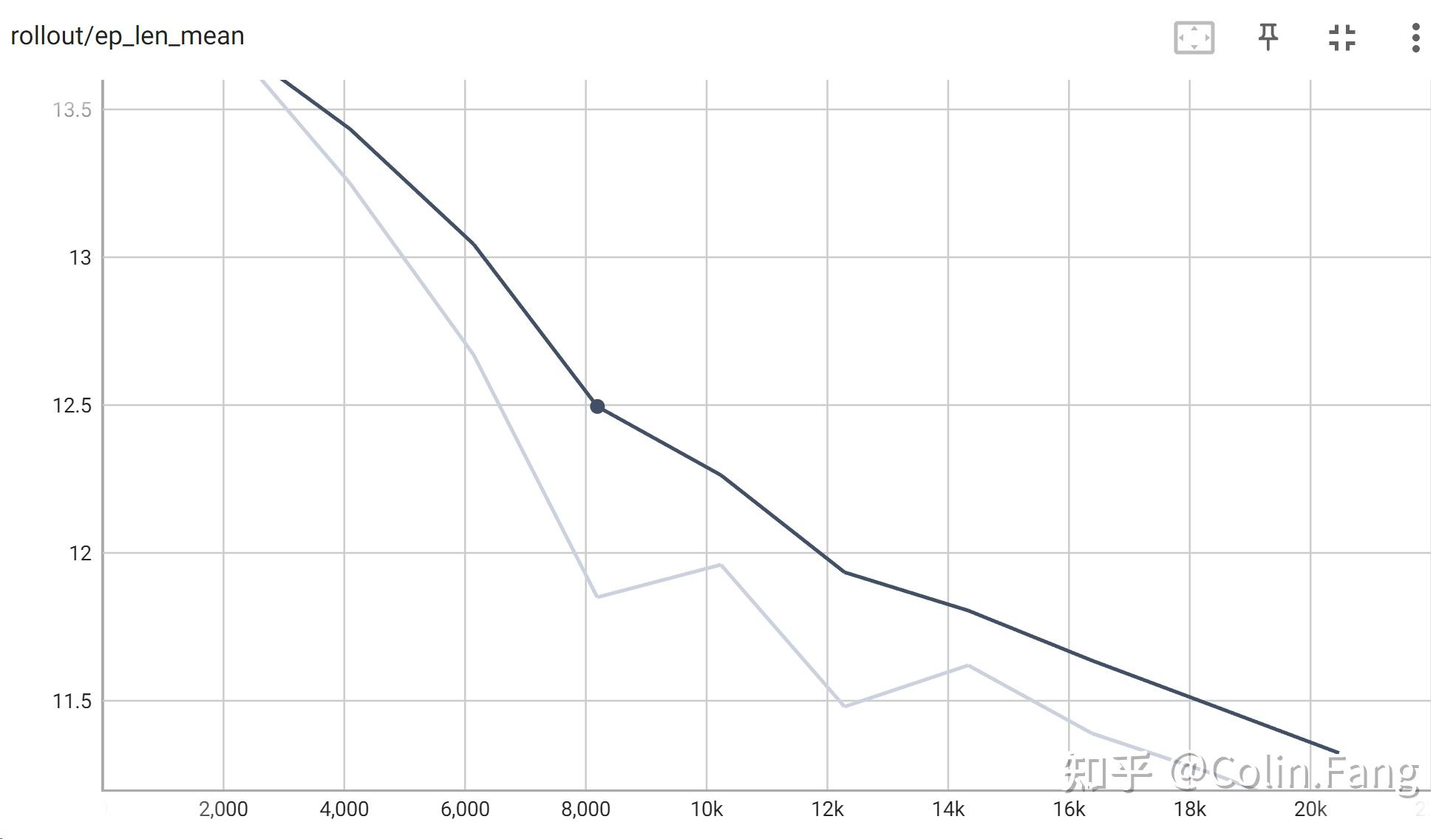
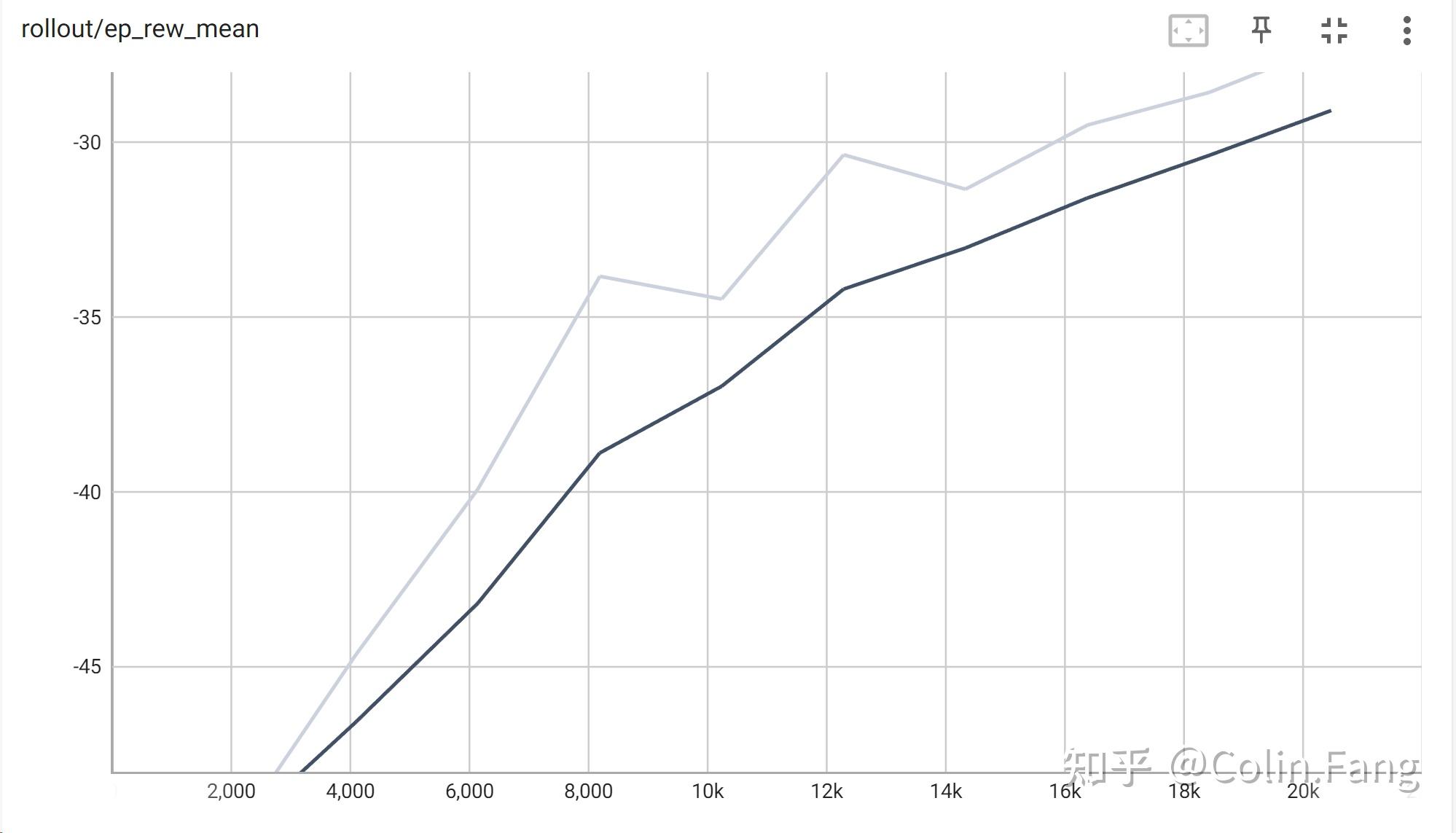
由图可知,随着训练步数的增加,平均步数逐渐下降,平均返回值逐渐上升。(未达最优,有兴趣自行训练)
模型测试:
if __name__ == '__main__':
args = get_args()
env = SumoGym(args)
ACTIONS_ALL = {
0: 'Lane keeping',
1: 'Lane change',
}
# load model
model = PPO.load("models/ppo1", env=env)
eposides = 10
for eq in range(eposides):
print("Test eposide:{}".format(eq))
obs = env.reset()
done = False
rewards = 0
counts = 0
while not done:
counts += 1
time.sleep(0.01)
action, _state = model.predict(obs, deterministic=True)
action = action.item()
obs, reward, done, info = env.step(action)
# env.render()
rewards += reward
print("The rewards is:{}, the counts is:{}".format(rewards, counts))测试结果:
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
Test eposide: 0
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 1
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 2
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 3
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 1ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 4
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 5
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 6
Loading configuration ... done.
Mission success!
Step #21.00 (1ms ~=1000.00*RT, ~2000.00UPS, TraCI: 1ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 7
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 8
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11
Test eposide: 9
Loading configuration ... done.
Mission success!
Step #21.00 (0ms ?*RT. ?UPS, TraCI: 2ms, vehicles TOT 2 ACT 2 BUF 0)
The rewards is: -26.506993450624154, the counts is: 11可看出训练后的模型,均能完成任务,成功率10/10=1.0。
测试视频:
 https://www.zhihu.com/video/1682913657346977793
https://www.zhihu.com/video/1682913657346977793以上为基于SUMO换道决策的小例子,本文的重点是sumo+gym+SB3的技术路线来实现强化学习的换道决策,其中动作空间、状态空间和奖励函数的设计较为简单,有较大优化空间,有兴趣者可进一步改进。
本文所有代码见码云:sumo-gym-lane-change
有啥问题,评论区见。
我们的团队人数
我们服务过多少企业
我们服务过多少家庭
我们设计了多少方案




