- 手机:138 0000 0000
- 传真:+86-123-4567
- 全国服务热线:400-123-4567


在优化模型的过程中,有高原、高峰、洼地,我们的目的是找到最低的那个洼地。
选择不同的学习率和优化器,可能进入不同的洼地,或者在洼地附近震荡,无法收敛。
Adam那么棒,为什么还对SGD念念不忘
https://blog.csdn.net/jiachen0212/article/details/80086926
学习率是深度学习中的一个重要的超参,如何调整学习率是训练出好模型的关键要素之一。
学习率决定了每步权重更新对当前权重的改变程度:
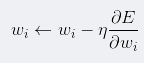
其中E(w)为我们优化的损失函数,η是学习率。
学习率太小,更新速度慢;学习率过大,可能跨过最优解。
因此,在刚开始训练,距离最优解较远时可以采用稍大的学习率,随着迭代次数增加,在逼近最优解的过程中,逐渐减小学习率。
太大容易出现超调现象,即在极值点两端不断发散,或是剧烈震荡,总之随着迭代次数增大loss没有减小的趋势;
太小会导致无法快速地找到好的下降的方向,随着迭代次数增大loss基本不变。

学习率调整方法基本上有两种:
基于经验的手动调整。 通过尝试不同的固定学习率,如0.1, 0.01, 0.001等,观察迭代次数和loss的变化关系,找到loss下降最快关系对应的学习率。
基于策略的调整。
2.1 fixed 、exponential、polynomial
2.2. 自适应动态调整。adadelta、adagrad、ftrl、momentum、rmsprop、sgd
方法如下:
https://blog.csdn.net/Cxiazaiyu/article/details/81837230
制定一个合适的学习率衰减策略。可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。
例子:
其中opt.lr_decay = 0.95
我们的团队人数
我们服务过多少企业
我们服务过多少家庭
我们设计了多少方案




