- 手机:138 0000 0000
- 传真:+86-123-4567
- 全国服务热线:400-123-4567


近期,大岩资本黄铂博士结合生活实践中的案例,深入浅出阐释了最优化算法的前世今生。
从实际生活中最基础的应用切入,黄铂将抽象的算法概念生动化,解释了什么叫最优化问题、凸优化及算法分类、机器学习与人工智能应用。
人生不如意之事十之八九,想达到我们想要达到的目标时,通常都有各种各样的限制。那么所谓最优化问题,就是指用最优的方式去平衡理想与现实之间的关系。
以简单的邮差送信问题为例,邮差从A出发,送信到BCD,最后回到A。邮差每天必须经过BCD,而且每个点每天只能经过一次,在这样的约束条件下,他的目标函数是尽可能以最短的时间完成送信。这个问题非常简单,只要把所有的路径枚举出来,然后取最短时间的方式即可。
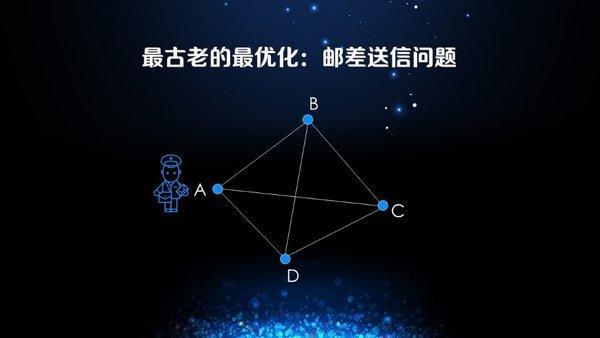
根据前面的例子,我们严格的将目标函数分为两大类。
第一类是最大化,包括最大化盈利,最大化效率。另一类是最小化,包括最小化费用、时间和错误率。在金融行业,我们可以最大化预测股价的正确率,也可以最小化费用、最小化时间和错误率。
当然,我们可以同时最大化盈利,最小化费用和时间。所以通常在很多的优化问题中,这两种任务可以组合起来出现在同一个问题框架下,这就是对于目标函数的定义。
关于约束条件,理想很美好,现实很骨感,在现实生活中,我们会遇到比如预算有限、时间有限、外部强制性条件等各种各样的问题,与目标函数一样,这些限制条件不是单一存在的,也可能同时存在同一个问题里,对于某一个优化问题来讲,限制条件越复杂,求解就越困难。
基于此,我们简单根据它的约束条件以及目标函数变量类型将最优化问题分成两大类,连续优化和离散优化。
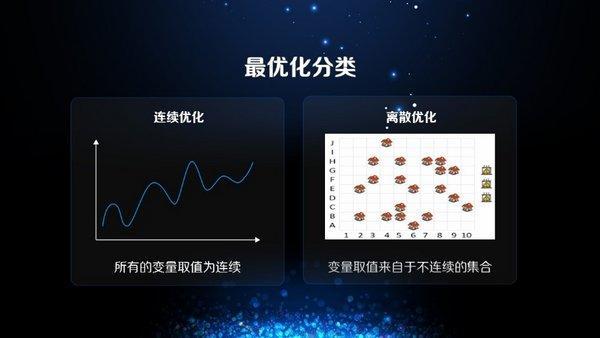
连续优化正如图上所画,线中间没有断点,而离散优化的变量取值,是一个不连续的记录,就如同一开始讲的邮差送信问题。
两类相较而言,离散优化会更难解决,因为离散优化多了一条限制条件 -- 不连续的集合。很多时候,我们要求我们的变量是一个整数,或者来自一个给定的区间,所以说离散优化会比连续优化更难解,而两种算法也会有非常大的不一样。
从学术角度而言,连续优化与离散优化对应的是两个比较独立的学科,离散优化可能更多的应用于统计、大数据相关的场景,连续优化则会跟计算机密码学相关,更多的与我们现实生活中的运筹优化应用相关。
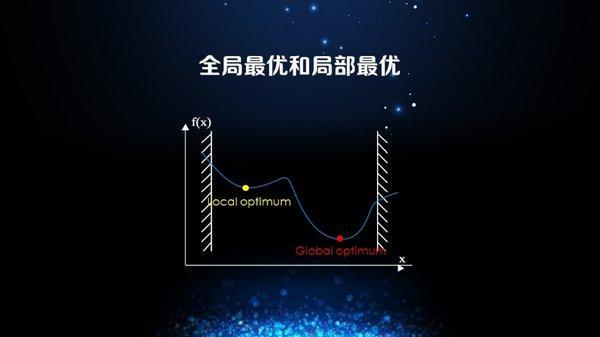
从目标函数出发,它的最优值也分为两类,局部最优和全局最优。我们看图中黄色的点,在局部区域内是最低的,我们管这个值叫做局部最优值,但是当我们看整个图时,红色的点才是最低的,所以这个点我们叫全局最优值。
通常来说,取局部最优值是相较容易的,因为基本上你只需要看它临近一小部分的信息就可以准确判断是否局部最优,而在现实应用中,其实仅仅知道局部最优值就足以解决很多问题。而更难的问题在于全局最优值,因为前提是你需要看到整个画面。
所以,对于这一类问题,我们目前没有一个特别好的解决方法。现实生活中,我们会有比较多的方法去求局部最优值,而往往我们找到的几乎跟实际上的全局最优值不一样。
但有一个问题是例外,这类问题它具有比较好的性质,只要找到局部最优值,它就肯定是全局最优值,这类问题就叫凸优化。

凸优化的关键字在“凸”,我们要定义什么样的东西是凸的呢?看上图,蓝色区域代表优化问题里变量可以取值的空间,当取值空间是凸的时候,这是凸优化的一个必要条件。
那么什么样的集合是凸的集合?我们在集合里任意选两点X、Y,我们将这两点连成线,从X到Y的这条线上所有的点都必须在集合里,只有这样的集合才叫做凸的集合。
相反,如果有任意一个点在集合之外,那就不是凸的集合。而对于一个凸优化的问题而言,它所有的变量取值必须来自于凸的集合。
所以说,对于所有的离散优化而言,它都不是凸优化的,因为它的取值其实不是一个空间,而是一个洞一个洞的,它是很多洞的集合。
所以,通常求解这类问题时很困难,很多时候我们求解的都是一个局部最优值。在实际生活中,我们求解的都是局部优化的问题,而这类问题在所有问题中所占比例是非常非常低的。
如果把整个集合看作一个优化问题的集合,那么相对来讲,比较小的一部分是属于连续优化的问题,其他更大的区域属于离散优化的问题,而在连续优化的空间里只有很小的一部分属于凸优化的问题。所以说,在最优化的领域里,我们真正解决的只是实际问题中的冰山一角。
对于凸优化的问题,黄铂博士给大家介绍几个最经典的算法。
第一个算法,最速下降法。首先,我们看下图,这是一个等高线,我们可以把它理解为我们的高楼,每一个圈代表一层,最中心是最高的位置,我们最终目标是用最快的方式上到中心位置。
那么,最速下降法是怎么做的呢?比如从一楼上二楼可以有多种方法,很明显我们从垂直方向往上跳,在局部来看是最快的,然后以这样的方法上到最高层。

最速下降法有哪些特点呢?每一步都做到了最优化,但很遗憾的是,对于整个算法而言,它并不是非常好的算法。因为它的收敛速度是线性收敛,线性收敛对于最优化算法而言是一种比较慢的算法,但也是凸优化里最自然的一个算法,最早被应用。
第二个算法,共轭梯度法。与最速下降法相比较(看下图),绿色的线是最速下降法的迭代,从最外层到中心点可能需要五步迭代,但是共轭梯度法可能只需两步迭代(红色线)。

共轭梯度法最大特点是汲取前面的经验再做下一步的动作,比如从四楼上五楼,我们会考虑方向是否最佳,汲取之前跳过的四步经验,再探索新的方向往上跳。从数学的角度来讲,每一步前进的方向和之前所有走过的路径都是垂直的,因为这样的性质,共轭梯度法的收敛速度远远高于最速下降法。
第三个算法,牛顿法。前面两种算法,从数学的角度讲,他们只用到了一阶导数的信息,对于牛顿法而言,它不仅仅用到了局部一阶导的信息,还用到了二阶导的信息。
相比前面两种算法,牛顿法的每一步,它在决定下一步怎么走时,不仅考虑当前的下降速度是否足够快,还会考虑走完这一步后,下一步坡度是否更陡,下一步是否更难走。可见,牛顿法所看到的区间会更远,收敛速度更快,属于二阶收敛速度。
如果最速下降法需要100步的话,牛顿法就只需要10步,但也正因为牛顿法使用了二阶导的信息,所以它需要更多的运算量。
第四个算法,拟牛顿法。1970年,Broyden、Fletcher、Goldfarb、Shanno四人几乎同一时间发表了论文,对于传统的牛顿法进行了非常好的改进,这个算法叫拟牛顿法,它的收敛速度与牛顿法相似,但是它不再需要计算二阶导数,所以每一步的迭代速度大大增加。
它是通过当前一阶导数的信息去近似二阶导数的信息,因此整个运算速度大幅度增加。由于这个算法是四个人几乎同一时间发现的,所以也叫BFGS算法。下图中的照片是他们四个人聚在普林斯顿时拍的,很幸运的是,Goldfarb是我博士时期的导师。
实际生活中,被应用最广的两种算法,一个是BFGS,另一个就是共轭梯度法。这两种算法经常会出现在很多的程序包里或者开源代码里,如果使用在大规模的优化问题或者成千上万个变量的问题中,也会有非常好的效果。
随着这些年大数据与人工智能的发展,最优化的算法也随之进一步发展,接下来几个应用可能更有意思。
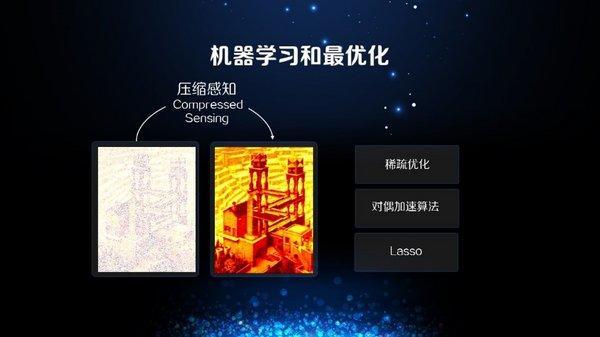
第一个应用叫压缩感知,首先我们把一个图去掉80%、90%的像素点,然后如何还原到原有的图片,这个问题看起来非常困难,但是在实际应用中,压缩感知的算法就有非常好的效果。与这个问题相关的,还有很多很优美的优化算法,比如稀疏优化,对偶加速算法、Lasso。
这个算法还有另外一个应用,人脸识别。看下图,这个图上是同一个人在做各种表情,甚至戴上墨镜,人脸识别通常会用在海关、捉拿罪犯。当我们原始输入的人脸有很多噪音时,它会通过最优化算法,将人脸画像出来,比如当输入的是戴有墨镜的人脸,算法会将墨镜和人脸分离开来。
同样的算法可以应用在背景分离,比如我们想要一张非常美的海景,但是又不想要太多人在这个照片上,那么就可以通过这个算法将人物和背景分离开。
看下图右侧,这是一个电梯口的监控录像,背景是静止的,而来来往往的人是动态的,通过最优化算法就可以将前景和背景分离出来。这项研究是在2009年由微软研究员的几名学者一起研究出来的。

最后一部分是深度学习。深度学习有很多层神经网络,这个算法在97年就已经被提出来了,但是之所以最近才会有非常大规模的应用,因为在算法上会有非常大的提高,我们可以通过GPU来进行加速运算。
另外,我们在优化算法上也有了非常好的进展。其相关的优化算法是随机优化,顾名思义,它不会优化所有的变量、所有的样本,而是随机挑选一个或者几个样本进行优化,然后在不需要看完整样本的情况下就可以有非常好的效果,可以大规模的提高模型训练速度。
最优化算法,源于生活高于生活,很多应用其实出现在我们每天的日常生活中,希望今天的演讲对大家有所帮助。谢谢大家。雷锋网雷锋网雷锋网
我们的团队人数
我们服务过多少企业
我们服务过多少家庭
我们设计了多少方案




