- 手机:138 0000 0000
- 传真:+86-123-4567
- 全国服务热线:400-123-4567


两种方法充分利用NMT中的源端单语数据:第一种,采用自学习算法生成用于NMT训练的大规模合成平行数据;第二种,使用2个NMT的多任务学习框架同时预测翻译和源侧单语句子的重新排序。
自学习算法:首先使用可用的对齐句子对来构建pipeline机器翻译系统,然后通过pipeline翻译系统翻译源侧单语句子来获取更多的合成平行数据。
多任务学习框架:将多任务学习框架应用于预测目标翻译和重新排序的源侧句子。思想:构建2个NMT,一个在对齐的句子对上训练,以从源句子预测目标句子;另一个在源侧单语语料库中进行训练以从原始源句子中预测重新排序的源句子(句子排序方法)。Notice:2个NMT共享相同的编码器网络,以便它们可以互相帮助以增强编码器模型。
发现:更多的单语数据并不总能提高翻译质量,只有相关的单语数据才有帮助。
关于自学习:
Step1:使用给定的双语数据Db构建基准机器翻译(MT)系统(可以使用任何翻译模型,SMT或NMT)
Step2:基线MT系统自动将源侧单语句子Dsm转换为目标翻译Dtt
Step3:合成的平行语料库Dsyn和原始的bitext Db组合在一起以训练新的NMT模型
此工作中重点关注翻译模型,我们将NMT用作基准MT系统。 注意,合成目标部分可能会对NMT的解码器模型产生负面影响。 为了解决这个问题,我们可以通过冻结用于合成数据的解码器网络的参数,在NMT训练期间将原始bitext与合成双语语句区分开。
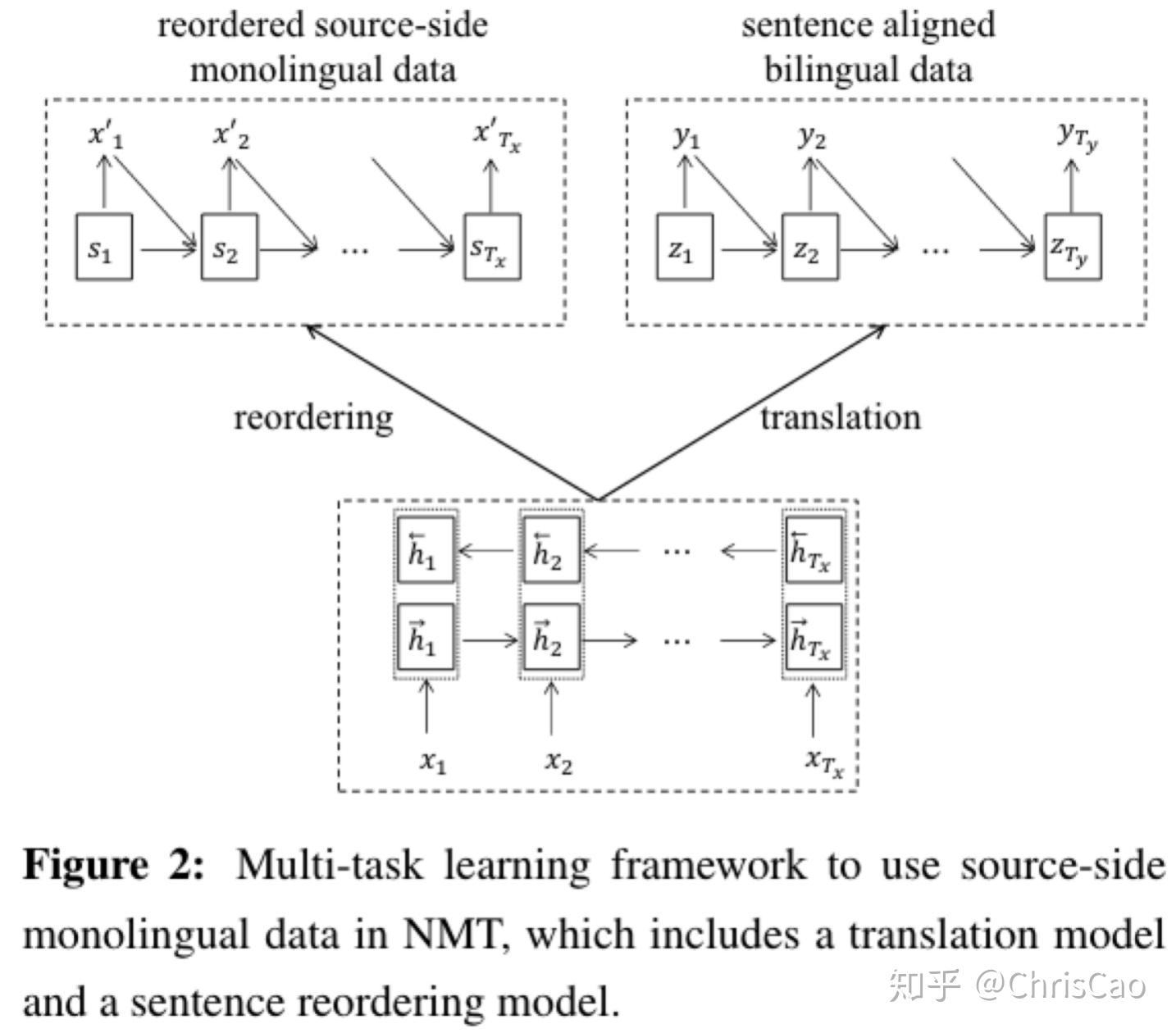
请注意,以上两个任务共享相同的编码器模型以获得源语句的编码。 因此,这种多任务学习的总体目标函数是机器翻译和句子重新排序的对数概率之和:
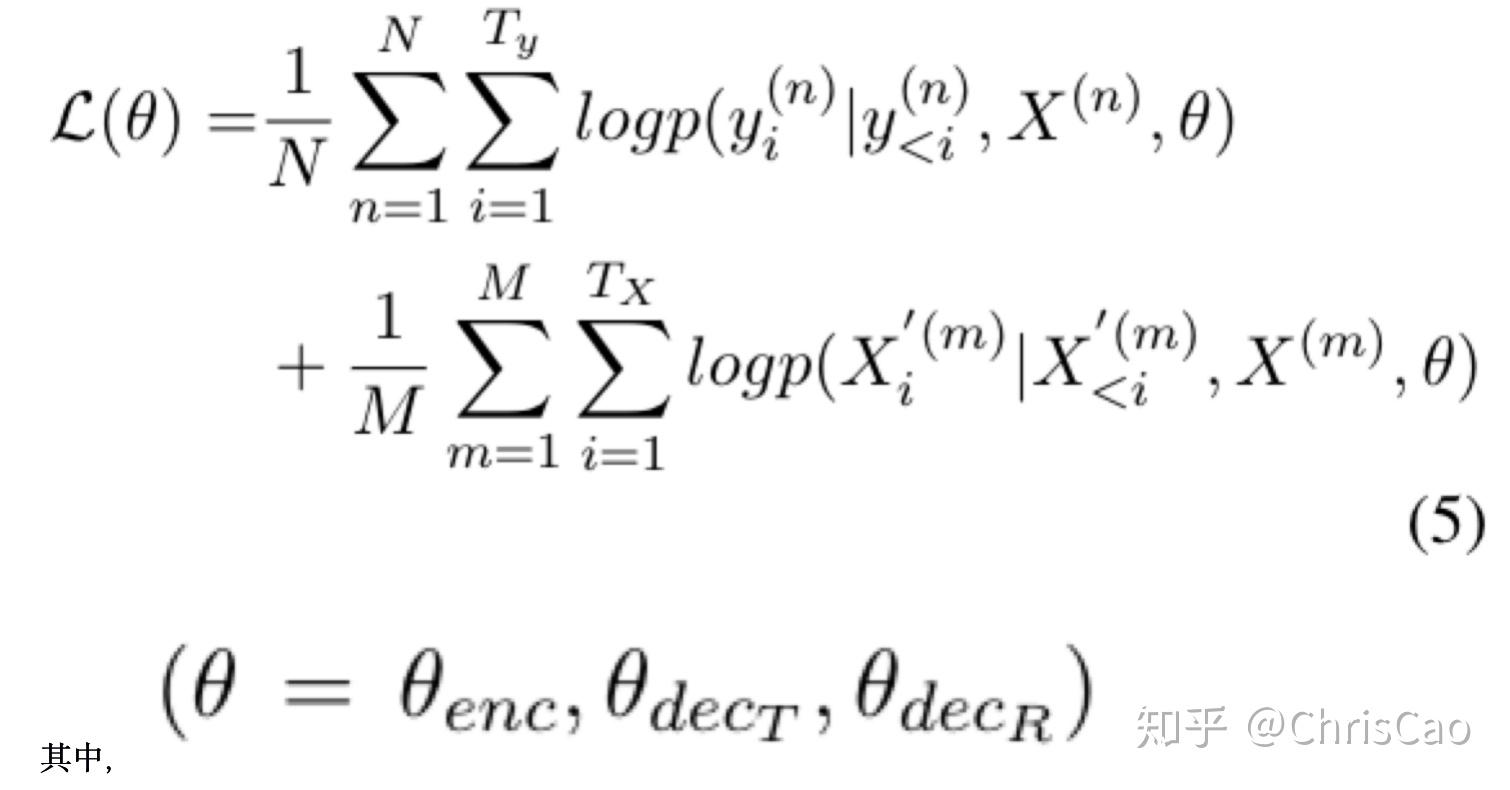
θenc是源语言编码器网络的参数集合,θdecT表示用于翻译的解码器网络的参数集,θdecR表示用于句子重新排序的解码器网络的参数。
与句子重排任务相比,本文更加关注翻译任务。 考虑到这些,我们在参数优化过程中区分了这两个任务。 它是使用替代迭代策略执行的。 对于每次迭代,我们首先将重新排序任务中的编码器-解码器网络参数优化一轮。利用学习到的编码器网络参数来初始化翻译任务的编码器模型。然后,我们在翻译任务中学习了几个epoch的编码器-解码器网络参数。 然后,新的编码器参数将用于初始化用于重新排序任务的编码器模型。 我们继续迭代直到满足约束条件(例如迭代次数或参数没有变化)。 缺点是该方法比自学习方法效率低。
对偶学习将BT方法扩展到在两个翻译方向上训练神经机器翻译系统。当联合训练源到目标和目标到源的NMT模型时,这两个模型可以提供彼此方向的回译数据,并执行多轮BT。该策略也成功地应用于无监督翻译系统的构建。
对偶学习用于解决人工标记昂贵的问题,使NMT系统通过对偶学习从未标记的数据中自动学习。在对偶学习机制中,一个智能体表示原始任务模型,另一个智能体表示对偶任务模型,通过强化学习让它们互相学习。根据互相学习过程中产生的反馈信号,迭代地更新这两个模型,直到收敛。
对偶学习机制能更有效地利用单语语料(源语言和目标语言),通过对偶机制,单语数据起到和平行双语数据相似的作用,并在训练过程中减少对平行双语数据的需求。
Firstly,通过强化学习来训练来自未标记数据的翻译模型,减少了对对齐后的双语数据的需求。
Secondly,对偶学习提取激励信号,可以在机器翻译等现实应用中进行强化学习。
从任何单语数据中的句子开始,首先将其向前翻译为另一种语言,再向后翻译为原始语言,根据翻译结果改进翻译模型,反复进行此过程,直至两个翻译模型收敛。
实验过程:我们使用双语数据对对偶NMT的训练进行了热启动。
在对偶学习的开始,对于每个mini-Batch,从用于训练初始模型的数据集中采样双语数据的一半句子和采样单语数据的一半句子,随着训练过程的进行,逐步增加mini-Batch中单语句子的百分比,直到完全不使用双语数据,目标是:根据单语数据和双语数据的可能性最大化加权和。
只要两个任务是对偶形式,我们就可以应用对偶学习机制,通过强化学习算法同时从未标记的数据中学习两个任务。
关键思想是形成一个闭环,这样我们就可以通过比较原始输入数据和最终输出数据来提取反馈信号。
提出了一种简单而有效的策略来利用两端的单语数据,该策略包括三个步骤:







有以下实证观察:
1)同时使用源端和目标端的单语数据比只使用一个领域的单语数据要好。
2)向大型合成bitext添加噪声会提高NMT的准确性。
3)通过噪声训练获得的模型的干净训练/调整进一步提高了其精确度。
4)我们的方法在2016年、2017年和2018年的英语?德语新闻和2019年的德语→法语新闻上取得了最先进的结果。
Bert-fuse模型的新算法,该算法先用Bert提取输入序列的表示,再通过注意力机制将表示与NMT模型的编码器和解码器的每一层进行融合。
首先将输入序列转换成由BERT处理的表示。然后,通过BERT-编码器注意模块,每个NMT编码层与BERT获得的表示进行交互,最终输出利用BERT和NMT编码器的融合表示;解码器的工作方式类似,将BERT表示和NMT编码器表示进行融合。
在这项工作中,我们将使用Transformer作为我们模型的基本架构。
(I)使用预训练的模型来初始化NMT模型。此方法有不同的实现方式:
(1)在(Devlin等人,2019年)之后,我们用预训练的BERT初始化NMT模型的编码器。
(2)在Lample&Conneau,2019)的基础上,我们用XLM对NMT模型的编码器和/或解码器进行了初 始化。
(II)使用预训练的模型作为NMT模型的输入。受(Peters等人,2018年)的启发,我们将最后一层BERT的输出作为其输入输入到NMT模型。
数据多样化方法,先在向后(目标--->源)和正向(源--->目标)翻译任务上训练多个模型,再使用这些模型从语言双方生成一组不同的合成训练数据,以扩充原始数据。



数据多样化方法是一种真正的数据增强方法,它将数据转换为遵循不同模型分布的合成翻译。
数据多样化牺牲了困惑度,以获得更好的BLEU得分。
提供带有空(或虚拟)源句的单语训练样本,或者提供单语训练数据,提供通过将目标句自动翻译成源语而获得的合成源语,我们称之为回译(目标--->源 的回译)。
可以将少量的域内单语数据反向翻译为源语言,以有效地进行域自适应。确定了域适应效果,减少了过度拟合并提高了流畅度,这是使用单语数据进行训练有效的原因。
半监督学习的神经机器翻译:
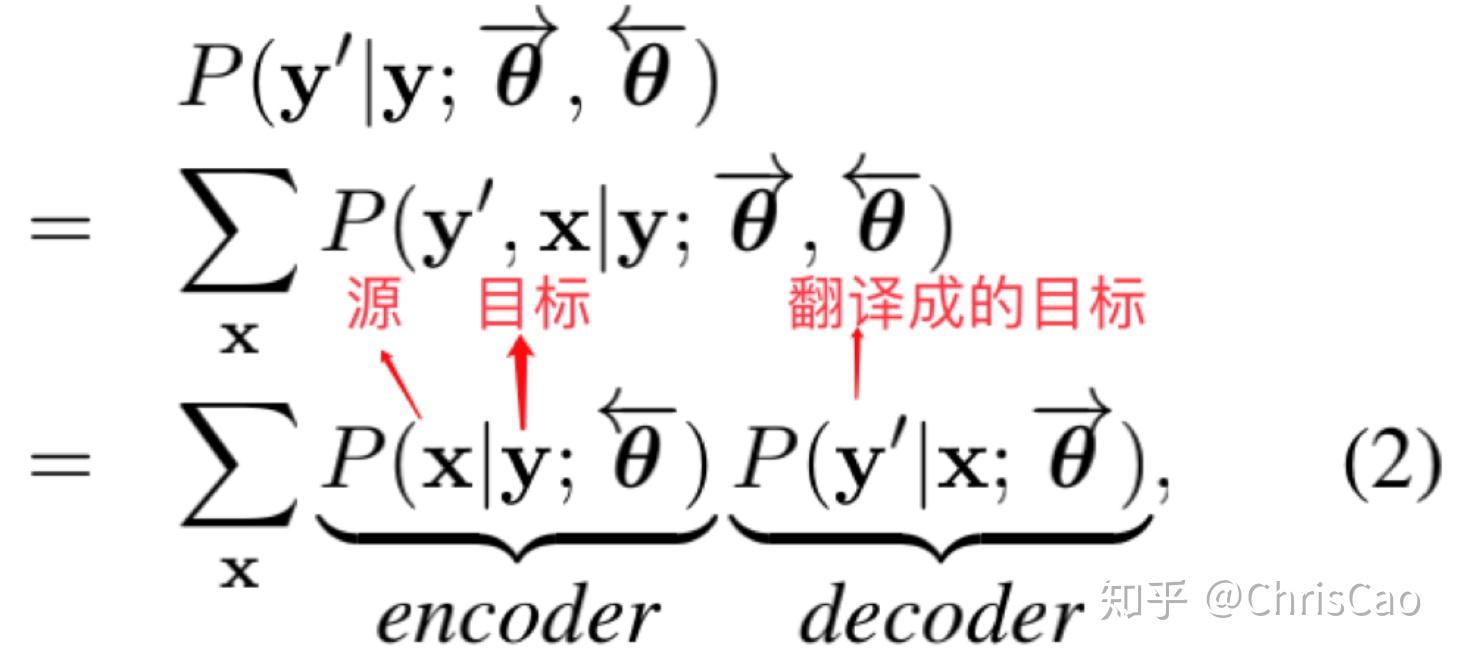
中心思想:使用自编码器重建单词语料库
自编码器:source--->target model:Encoder
target--->source model:Decoder
NMT直接对给定的源语句子的目标句子的概率进行建模。
Sennrich等.(2015)提出了两种方法来开发对网络架构透明的单语语料库:
way1:将单语句子与虚拟输入配对。Embedding参数和attention模型在训练这些伪平行句子对时是固定的。
way2:现在平行语料上训练一个NMT model,再用这个学习的模型来翻译单语语料。这个单语语料库及其译文构成了一个额外的伪平行语料库。
本论文提出了半监督学习的NMT:给定labeled(平行语料)& unlabeled(单语语料)数据;
联合训练source--->target & target--->source翻译模型。
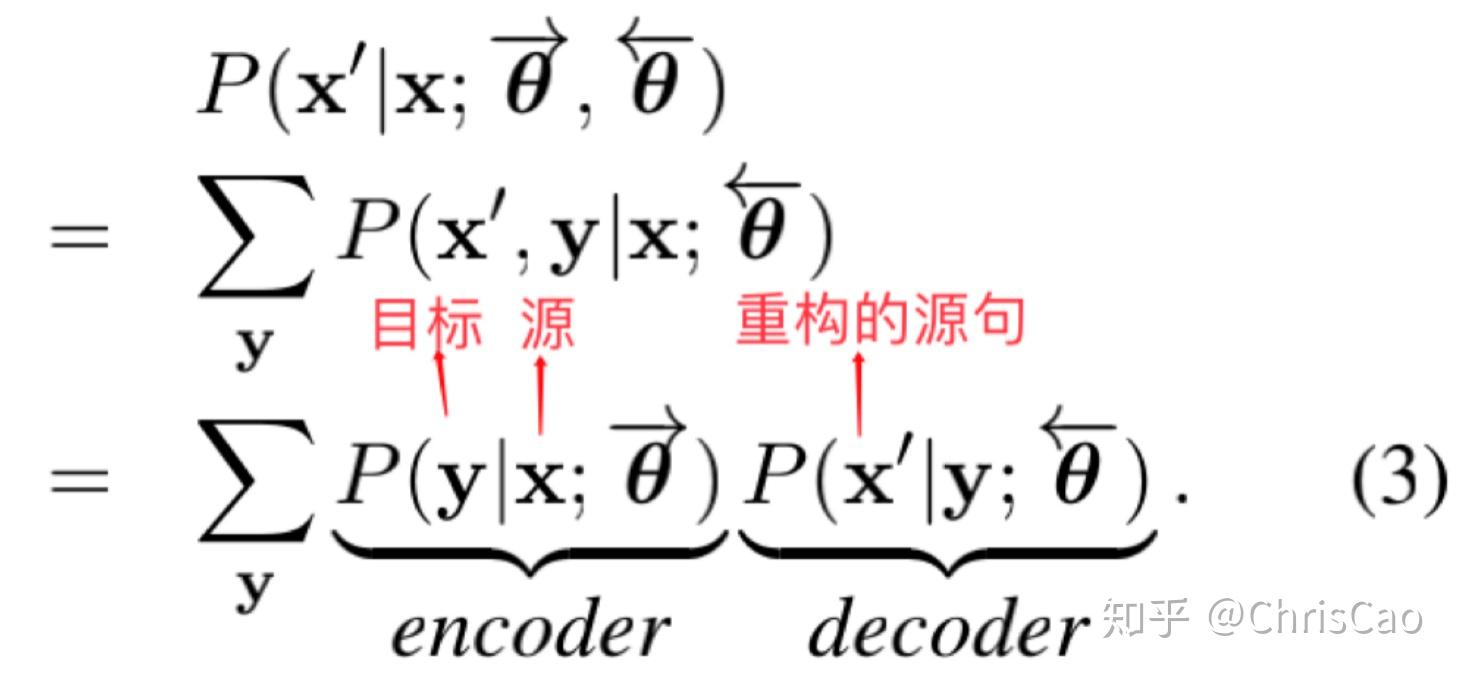
核心思想:在训练目标上附加一个重构术语,旨在使用自编码来重构观察到的单语语料;对全搜索空间进行采样来提高搜索效率。

如何在单语语料上训练无监督?用自编码器
1)用target--->source编码器 model 编码观察到的目标sentence为一个隐源sentence。
2) 用source--->target解码器 model解码这个源sentence来重建这个观察到的目标sentence。
目标自编码器:x:隐源句子
源自编码器:
半监督学习


lambda1,lambda2是超参,用于平衡likelihood和autoencoders。

我们的方法能用丰富的源语言和目标语言的单语语料库,利用小批量随机梯度下降来训练联合模型。
平行语料库中的小批量数据+随机从源语料库和目标单语语料库中选择句子,构建2个额外的mini-batch。为降低复杂度,使用译文质量最好的topk(一般取k=10),平衡了翻译质量和效率。
使用了平行语料+源&目标单语语料,使 源--->目标 和 目标--->源 模型能在平行语料库和单语语料库上进行交互。
选用target autoencoder时,取 lambda1=0.1,lambda2=0;
选用source autoencoder时,取lambda1=0,lambda2=0.1;
渐变裁剪阈值设为0.05,模型参数通过在平行语料上训练的模型来初始化。

OOV ratio表示了单词句子与平行语料库的相似程度,OOV ratio越小,说明单词句子与平行语料库的相似程度越大,根据句子对构建了相同大小的四种单语语料库。
使用在单语语料库中低的OOV ratio提升BLEU得分。
1).添加目标单语语料库比仅使用平行语料库进行source--->target翻译的效果要好。
2).添加源单语语料库也比仅使用平行语料库进行源--->目标翻译的效果提升了,但提升幅度小于添加目标单词的语料库。
3).同时添加源语料库和目标语料库=不会带来更大的改善。
我们的方法专注于通过单语语料库上的AutoEncoder学习双向NMT模型。
完全消除了对并行数据的需要,只依赖于单语言语料库。包括一个略微修改的注意编解码器模型,该模型可以仅在单语语料库上使用去噪和反向翻译相结合的方式进行back translation。
以去噪和即时的回译两种策略以无监督的方式训练整个系统。
在现有的关于无监督跨语言嵌入的工作(Artexe等人,2017;Zhang等人,2017)的基础上,将它们合并到一个改进的注意力编码器-解码器模型中,通过使用具有这些固定跨语言嵌入的共享编码器,我们能够结合去噪和back translation仅从单语语料库中训练系统。
我们的团队人数
我们服务过多少企业
我们服务过多少家庭
我们设计了多少方案




