- 手机:138 0000 0000
- 传真:+86-123-4567
- 全国服务热线:400-123-4567


相关信息
期刊 & 年份:arXiv && 2019
作者:Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He
引用量:330
相关链接:https://arxiv.org/pdf/1910.02054.pdf
阅读记录:2023年3月27日
ZeRO(Zero Redundancy Optimizer)名字的含义是"零冗余的优化器",即减少了训练时在数据并行和模型并行中的冗余,可能能够达到千亿级别的参数(Megatron是百亿)。
超线性加速:GPU数量增加N倍,加速效果超过N倍。
在NLP中,transformer为一系列大模型奠定基础:
| 模型 | 参数大小 |
|---|---|
| Bert-large | 0.3B |
| GPT-2 | 1.5B |
| Megatron-LM | 8.3B |
| T5 | 11B |
DP(Data Parallelism)
现有的DP技术不会减少每个设备的内存,当前的带有32GB内存的GPU,训练参数超过1.4B的模型就会内存耗尽。
MP(Model Parallelism)
MP垂直分割模型,将每一层的计算和参数划分到多个设备上,需要在每一层之间进行通信。因此,它们在GPU通信带宽高的单机中效果不错,但是在多机中,效率会迅速下降。
根据分析,在现有的模型训练中,主要有两处容易消耗内存:
ZeRO主要针对以上两个问题进行优化。
这部分主要介绍减少深度学习训练中内存使用的几种方式。
主要手段有:
这个方法存在的问题是PCI-E的限制容易影响CPU内存的带宽。所以ZeRO在大部分情况下不会把状态存到CPU,只在极少数情况下,ZERO-R将大的模型的激活点检查点放在CPU上,以提高性能。
通过保持模型参数和梯度的粗粒度统计来减少自适应优化方法的内存消耗,但是不确保模型是否会收敛。ZeRO与这样的方法是正交的。
自适应优化方法对于实现SOTA和大模型的有效训练至关重要。与SGD(随机梯度下降)相比,通过为每个模型参数和梯度维护细粒度的一阶和二阶的统计信息,需要以内存消耗为代价。ZeRO可以减少这些优化器的内存占用。
DP有很好的计算通信比 ,但是内存占用大(因为要保存整个模型);MP内存占用小,但是计算通信比低。不管怎么样,这些方法都静态维护整个训练过程中所需的所有模型状态,但是在训练过程中并非所有模型状态都是必须的。针对于此,作者设计一种ZeRO-DP方法(ZeRO-powered data parallelism)
对于这里的模型状态冗余,作者给出一个以参数量为Adam为例的混合精度训练示例:
共 ,对于一个有15亿参数的GPT-2来说,需要24G的内存。其实模型更新中只有3GB的内存需要维护(用于梯度),剩下的21GB在数据并行时不需要使用,但仍然需要存储。
解决方法:将模型参数均分到多个GPU,计算时向有所需参数的GPU索取。(类似于参数服务器的思想)
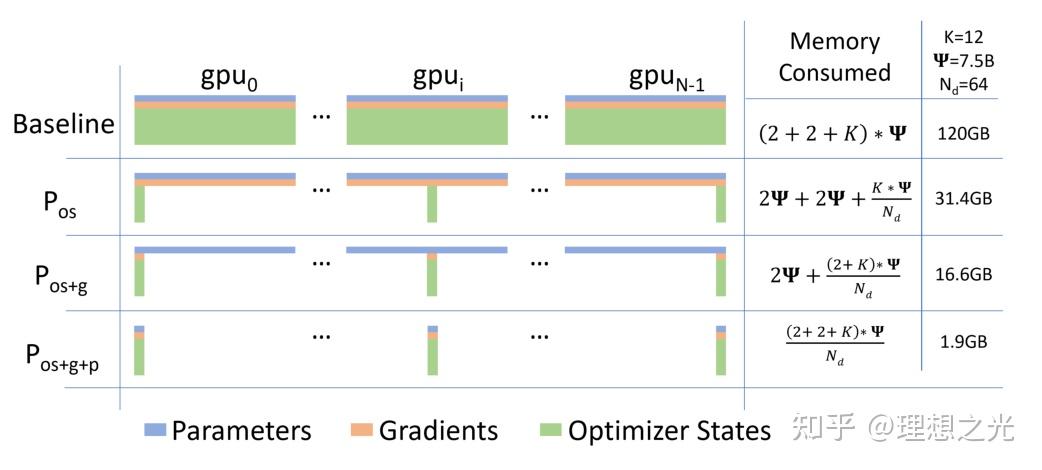
上图是进行模型状态优化后的结果,可以看出在有N个GPU的情况下,Baseline的内存消耗为 。
ZeRO-DP有三种操作:优化器划分、梯度划分和参数划分,与此对应的是消耗的内存不断被N个GPU平摊,所以减少内存占用。
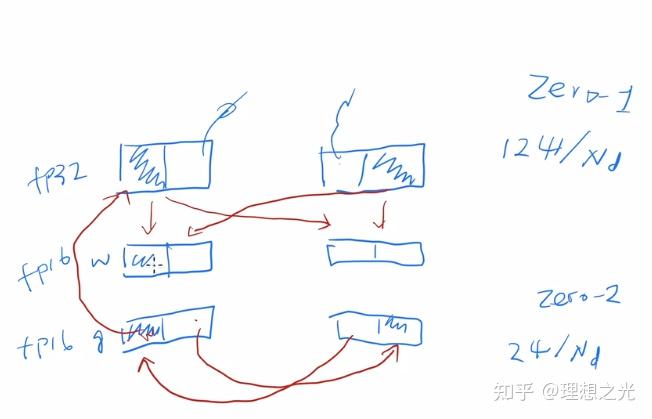
通信方式如上图所示,假设有两块GPU(GPU0和GPU1):
剩余状态的冗余主要发生在:
针对于此,作者设计一种ZeRO-R方法。
解决方法:
:Partioned Activation Checkpointing
模型并行要求activation的复制,导致在MP上activation的冗余。ZeRO通过对activation进行切分来消除这种冗余,即在计算出正向传播后就对activation切割,直到在反向传播时再次需要它,则用all-gather重组activation。
:Constant Size Buffers
在训练中,一些运算的效率与输入大小息息相关。比如一个大的all-gather操作会比一个小的all-gather的效率更高,Megatron这些库就会在这些运算前将参数全部融合(可以类比TCP/IP协议中的收发窗口)。但是随着MP复杂度增加,对内存也越发high demand。所以ZeRO设置一个固定大小的缓冲区来解决这个问题。
:Memory Degramentation
PyTorch在创建变量时就会开辟内存,发现变量没用后就会析构,会导致大量的内存碎片。内存碎片带来两个问题:1. 没有那么多的内存可用。2. 花大量的时间搜索可用内存。ZeRO的做法是为activation checkpoint和gradients预先分配连续的内存块。
我们的团队人数
我们服务过多少企业
我们服务过多少家庭
我们设计了多少方案




